Daniel Morales's Blog
Fancy words in Tech Episode II: GraphQL
February 2, 2023
TLDR: Server and Client Example https://github.com/danielm/graphql-example
What is it, and what's good about It?
It a way for a client to talk to a server in a shared language, usually defined via an schema, to query that server for data, or mutate that data remotely.
The core promise is that schema => or we can call it a contract. Here, Backend and frontend teams should agree on that schema, figure out needs and define what the needs of the application are.
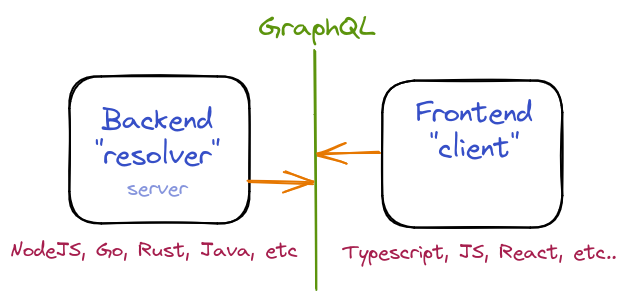
As you can see is a layer, or more like a "wall" between the server and the client (backend/frontend); where it doesn't matter what tech stack is your backend or client are using, they are completely independent; all they share is what they want from each other: the schema (a contract)
Differences with REST
- Uses a single entry endpoint, that uses a query language to interact with the server.
- Views the data as a graph structure, where objects are connected by relationships. Different from REST, where you got multiple resources on different endpoints not related to each others.
- We can specify what data we want back from the server, and what parts of the graph we want to retrieve. Example, from the client we can tell: "hey, we need the title, date and author fields from Posts, and from the Author just the name".
- Security: trying to do something not specified on the schema --> error
- Very good on long-living Frontend apps.
- It's meant to be an all-in-one schema solution, that describes everything a client can do.
- What a client can or cannot do, shouldn't be based on permissions, we have to assume everything is public (to some extent) and every user can see all possible actions.
Interacting withe the Server
- Query: Retrieve data.
- Mutation: Alter something on the data: Create/edit/delete/etc..
Schema example
This is what the client and the server must 'agree' on, it has a very simple syntax... very easy to understand just by reading it.
Internally GraphQL has many built in types and we (of course) can define many more.
So lets pretend we want to develop just another ToDo list:
type Task { // Our type
id: ID!
content: String!
completed: Boolean = false
}
type Query {
tasks: [Task] // a) Give me all Tasks, (an array of Task)
task(id: ID!): Task! // b) Give me one single Taks (by Id) '!' bang means required
}
// a type of payload to recieve when updating a task, note both are optional
input TaskPayload {
content: String,
copmleted: Boolean,
}
// c) and our mutation
type mutation {
update_task(id: ID!, payload: TaskPayload!): Task
}Here our back-end team will have to implement 3 "resolvers":
- resolve_tasks --> returns a collection of Task
- resolve_task --> returns a single Task by id
- update_task --> a mutation to edit either of the Tasks fields
What is it not? / Cons of GraphQL
- It is NOT SQL
- Communication between services/microservices of your stack. By design is a way to expose the logic of your backend, to your frontend apps.
- Suffers from n+1 problem when retrieving data; backend will have to go and implement solutions for this, like grouping resolvers, caches, etc.. Example: If we request all posts, and on each post we have an 'author' relation, it will generate a Query for each author of each post.
- It can be easy to fall into HELL when dealing with advanced relationships, (related to the previous point)
Conclusion
It is great when you want a tight integration between both sides of the APIs, but don't want to both implementations mixed.
Many clients like Apollo implement stuff like caching, subscribe to changes, etc. It becomes some sort of state manager, and with the use of useQuery() for TS/JS makes the usage from the back-end extremely easy.

I'm a 32-years old programmer and web developer currently living in Montevideo, Uruguay. I been programming since I was about 15 y.o, and for the past 12 actively working in the area.